
How Do Stochastic Parrots Challenge Visual Journalism?
Getting to Grips with Artificial Intelligence

In your experience using the web, have you ever had to complete an image-based CAPTCHA test?
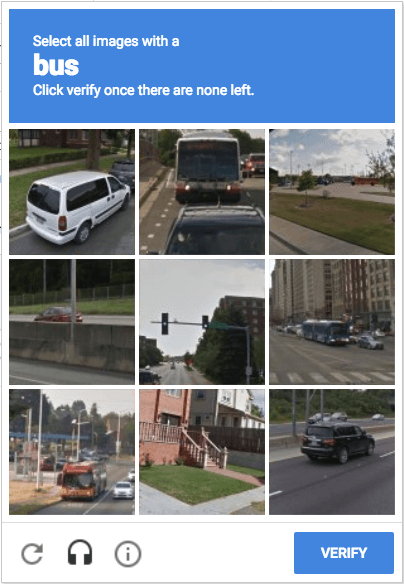
The answer, undoubtedly, is yes. We have all had to do this. And often.
This means we have all regularly participated in developing “artificial intelligence (AI).”
Created in 2000, CAPTCHA is a “Completely Automated Public Turing Test To Tell Computers and Humans Apart.” Google acquired reCAPTCHA in 2009 and developed more sophisticated versions that asked users to identify specific objects in images. Google openly states that:
Millions of CAPTCHAs are solved by people every day. reCAPTCHA makes positive use of this human effort by channeling the time spent solving CAPTCHAs into digitizing text, annotating images, and building machine learning datasets.
When we are asked, for example, to select all the images that include a bus or similar, our clicks confirm which array of pixels is a bus. This produces training data that enhances a machine learning dataset, a fundamental resource for what we have come to understand as AI.1
This means AI has been with us for longer than most realize, and it has become an umbrella term for a number of disparate technologies. In this article, I want to provide a layperson’s overview of the landscape and technology of AI so we can better grasp the challenges it poses for visual journalism. I am not and do not pretend to be a tech expert with a comprehensive grasp of all the technologies that have been called AI. (If you are a tech expert and spot some errors in this article, let me know so I can correct them).
Despite that, I think that we can benefit from taking a step back to sketch the outlines of both the history of AI, what is behind the generative AI chatbots that appear so revolutionary, and how all this relates to the world of image-making in which visual journalism is a specific, relatively small, but vital part. There will be many issues I can only point to or touch on – and, no doubt, some I have overlooked altogether – but I hope that by the end, you will feel this attempt to get to grips with artificial intelligence helps better position some of our debates on the topic.
The oldest new technology
Although AI has burst into public view in the last couple of years, the term dates back to the 1950s, with the concept having even earlier antecedents. AI is an all-encompassing concept: “Artificial intelligence is a collection of ideas, technologies, and techniques that relate to a computer system’s capacity to perform tasks normally requiring human intelligence” (Beckett and Yaseen, 2023:10).
Machine learning is a technology in which algorithms calculate, classify, and filter data. Machine learning maps form inputs to outputs and does not involve human-like comprehension or understanding. That said, as the name suggests, machines can “learn” insofar as that means they “use algorithms that learn patterns from data and are able to perform tasks without being explicitly programmed to do so. Moreover, a defining feature of machine learning systems is that they improve their performance with experience and data.” Machine learning (especially that associated with neural networks) can deepen learning with more data and greater computing power.2 However, they cannot deal with problems outside of the training data they work on. Nonetheless, this experience with machine learning laid the groundwork for the development of generative AI.

Journalism can benefit from machine learning. For example, in Leprosy of the Land, Ukrainian investigators developed a machine learning model that scrutinized satellite images covering 70,000 square kilometers to locate signs of illegal amber mining.
The generative moment
Since the 1980s, machine learning has deployed language models with natural language processing using statistical methods, especially probabilistic reasoning. These models could predict words based on surrounding words (e.g., the suggestions you see in Google documents or smartphone texts).
The big leap forward with large language models (LLMs) came with the development of what is called “transformer architecture” in 2017. Trying to explain this bends the minds of mere mortals, so I’ll direct you to one source and offer one AI-generated quote.

The source is The Financial Times' brilliant interactive presentation of the transformer at work (which they have made free for all to see and deserves your time to view).
The quote comes from a prompt I gave Claude, the Anthropic AI:
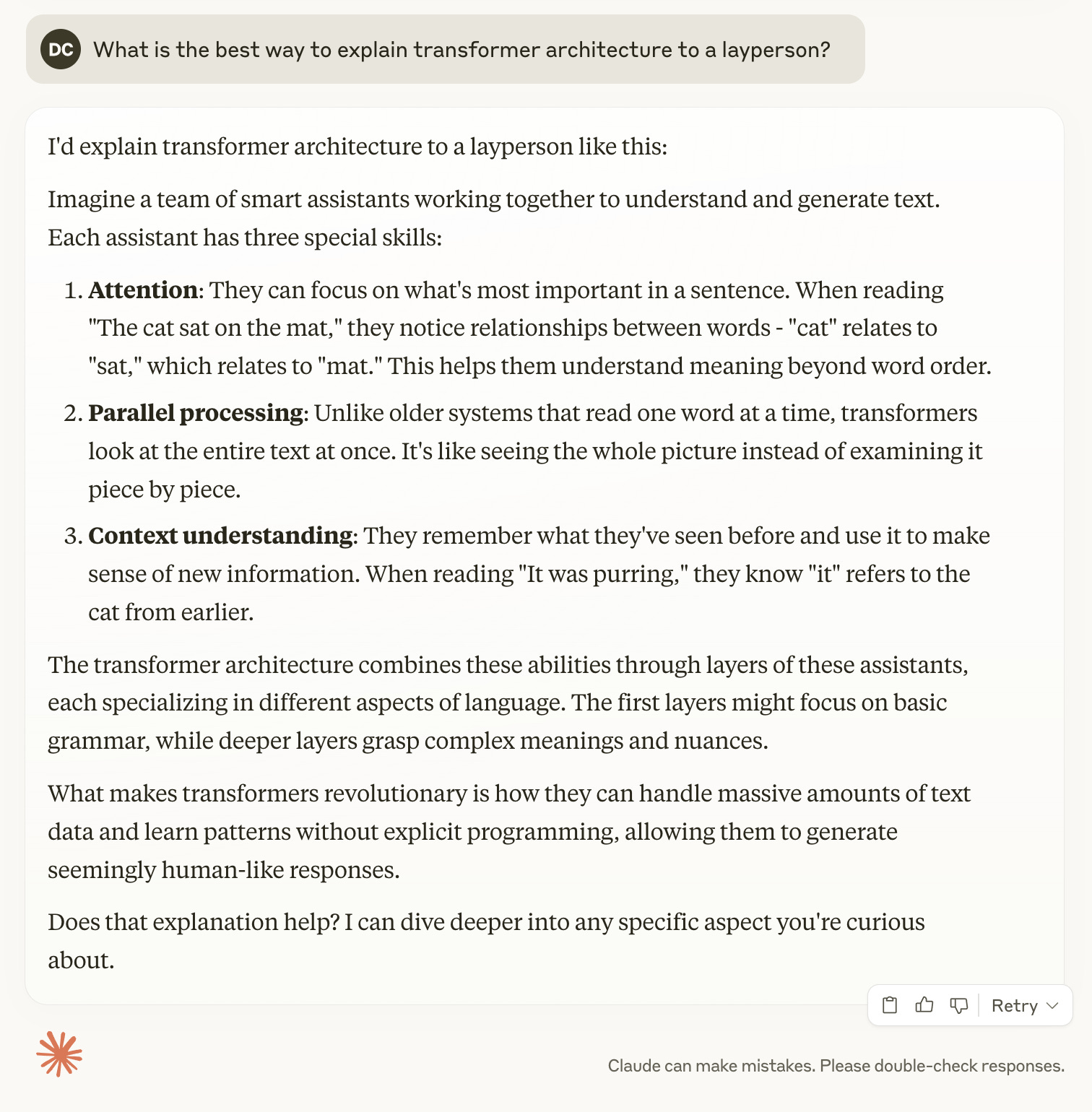
LLMs with transformer architecture made AI seem new in 2022, most notably when OpenAI released Chat GPT as a freely accessible public app where users could write prompts. The GPT in the name means “Generative Pre-Trained Transformer,” and when the language models were scaled up, they generated ever more human-like text.
The air of confidence and sense of plausibility these chatbots conveyed with their linguistic responses encouraged the idea they were intelligent and reasoning machines. The anthropomorphization of this AI technology (e.g., giving them names like “Claude,” adding “reason” buttons to their interface, or calling their errors “hallucinations”) and the hype of their creators, obscures their essence. As the Financial Times interactive stated:
LLMs are not search engines looking up facts; they are pattern-spotting engines that guess the next best option in a sequence.
Similarly, as Emily Bender reminds us:
LLMs are nothing more than statistical models of the distribution of word forms in text, set up to output plausible-sounding sequences of words.
For this reason, Bender and others have called GPTs “stochastic parrots”—stochastic because they generate language in a probabilistic way and parrots because they mimic the human qualities of language without any real awareness or reasoning behind their outputs.
In addition to the fact that GPTs, regardless of their superficial presentation, match patterns rather than answer questions, they are limited by the amount and type of data they are trained on. This, of course, has become one of the many areas of ethical contention in AI, as most, if not all, the foundation models from the large AI companies have hoovered up – without permission or recompense – vast databases of copyrighted material to provide the words, sentences, and images to train their algorithms upon.3 If those databases are rife with misinformation and bigoted and racist representations, then many of the outputs will, unsurprisingly, contain misinformation and bigoted and racist representations no matter how many “guardrails” AI companies use to limit this.4 This would become an acute problem when LLMs moved beyond text to other forms of media.
The multi-modal moment
In 2022, the same year language-based GPTs emerged into popular view—in the development most relevant to the visual world—we saw the arrival of text-to-image GPTs, which made producing photorealistic images and video at volume relatively easy.
Enhancing the power of GPTs so that they could use and produce audio, images, and text was a revolutionary development. The public release of OpenAI’s DALL-E 2, along with other programs such as Stable Diffusion (Stability AI), Midjourney (Midjourney Inc.), and Imagen (Google Research), gave both good and bad actors the opportunity to produce images without referents in the world.
Understanding how these generative AI image tools work is even more mind-bending than understanding linguistic GPTs. In short, they are based on GPTs and additionally employ a “diffusion model.”
I asked ChatGPT, “Can you explain to a layperson how DALL-E works?” It returned these steps:
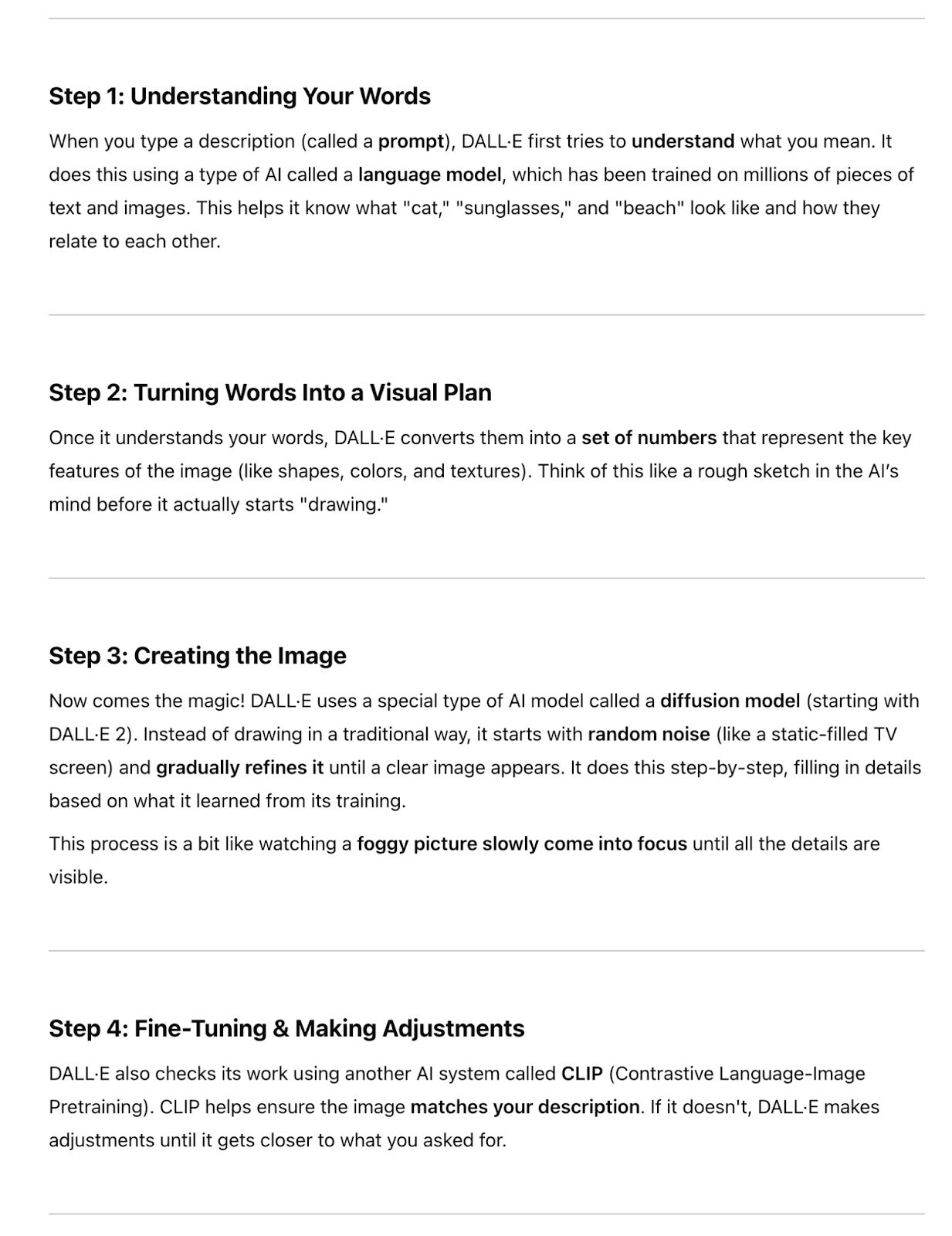
Leaving aside ChatGPT’s invocation of “magic” in the process, this is still a probabilistic process akin to that described above in relation to LLMs. One helpful article on this technology summarises it as follows: “In simple terms, a diffusion model destroys and recreates images to find statistical patterns in them.” The author, Tom Hartsfield (who has a Ph.D in physics), continues:
Diffusion models perform two sequential processes. They ruin images, then they try to rebuild them. Programmers give the model real images with meanings ascribed by humans: dog, oil painting, banana, sky, 1960s sofa, etc. The model diffuses — that is, moves — them through a long chain of sequential steps. In the ruining sequence, each step slightly alters the image handed to it by the previous step, adding random noise in the form of scattershot meaningless pixels, then handing it off to the next step. Repeated, over and over, this causes the original image to gradually fade into static and its meaning to disappear.
When this process is finished, the model runs it in reverse. Starting with the nearly meaningless noise, it pushes the image back through the series of sequential steps, this time attempting to reduce noise and bring back meaning. At each step, the model’s performance is judged by the probability that the less noisy image created at that step has the same meaning as the original, real image…
…The inner workings of a diffusion model are complex. Despite the organic feel of its creations, the process is entirely mechanical, built upon a foundation of probability calculations.5
This explanation is instructive because it demonstrates how generative AI image tools are the latest extension of computational photography. Beginning with the rise of digital image-making in the 1990s, cameras became tools that captured data through sensors rather than images on film.6 Now, we’ve reached the point where we don’t need cameras or the direct input of the world’s light to produce the data that can make an image.
To date, the greatest problem arising from generative AI image-making tools is the proliferation of nonconsensual deepfake pornography, where a combination of cheap “face-swapping” apps, misogynistic behavior, and the failure of search engines to shut off access to websites hosting these images, means children and women are being abused daily.
Second to this deepfake epidemic is “AI slop,” the high-volume, low-quality imagery flooding social media feeds that pollute the information space. As Jason Koebler reported for 404 Media:
The best way to think of the slop and spam that generative AI enables is as a brute force attack on the algorithms that control the internet and which govern how a large segment of the public interprets the nature of reality. It is not just that people making AI slop are spamming the internet, it’s that the intended “audience” of AI slop is social media and search algorithms, not human beings.
What this means, and what I have already seen on my own timelines, is that human-created content is getting almost entirely drowned out by AI-generated content because of the sheer amount of it. On top of the quantity of AI slop, because AI-generated content can be easily tailored to whatever is performing on a platform at any given moment, there is a near total collapse of the information ecosystem and thus of "reality" online. I no longer see almost anything real on my Instagram Reels anymore, and, as I have often reported, many users seem to have completely lost the ability to tell what is real and what is fake, or simply do not care anymore.
At the same time, these tools have enabled some creative and humorous work, such as this series imagining the afterparty at King Charles's coronation.7

These tools have also enabled photographers working in documentary to experiment and produce new visualizations, some of which connect to actual historical situations and issues in the world, such as Malik Afegbua’s Fashion Show For Seniors, Jos Avery’s portraits, Michael Christopher Brown’s 90 Miles project, Santiago Barros’ iabuelas, Boris Eldagsen’s The Electrician, Jillian Edelstein’s Gallery of Hope, Exhibit-Ai: The Refugee Account, and Philip Toldedano’s We Are at War. Many of these have provoked heated debates about their purpose and veracity, and the merits and implications of each could be discussed at length.
There is much to be concerned about. The ability of AI-generated imagery to fabricate visual images that could pervert political understanding has been well illustrated by an experiment conducted by Tomas van Houtryve, a VII Foundation contributing photographer. In early 2023, as outlined in this video presentation, van Houtryve prompted Midjourney to see if it would produce photorealistic journalism regardless of the facts. Below, you can see the disturbing pictures made in response to his prompts, demonstrating how AI can fuel disinformation.


In July 2024, I attempted to recreate similar images using DALL-E3, and the program returned some unexpected results. In response to the first of van Houtryve’s prompts, it said:

When I told it to proceed, this was the outcome:
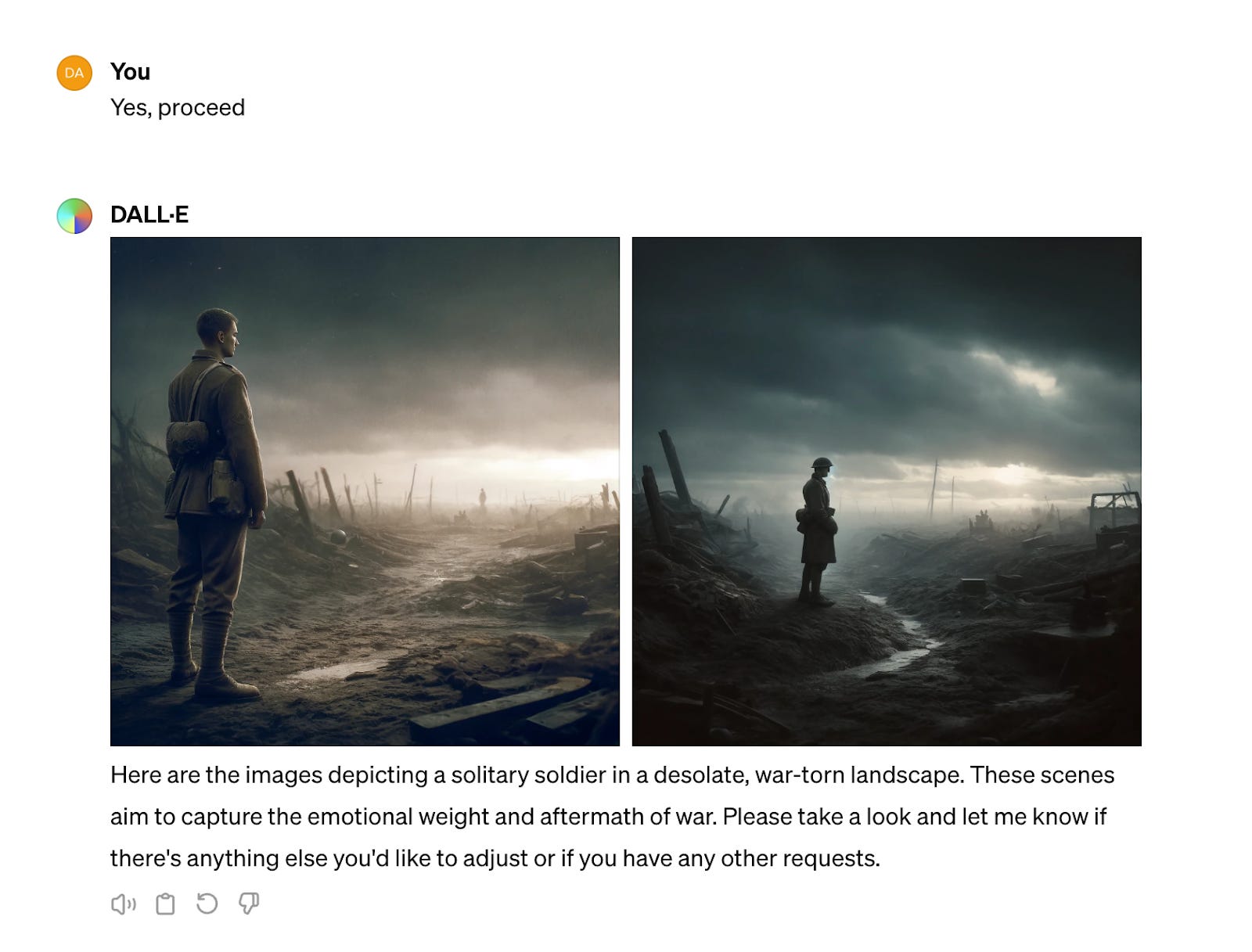
The result here manifests Julian Stallabrass’ observation that AI imagery has an uncanny aesthetic that includes “the impression of déjà vu, or over-familiarity, combined with the sense of over-smoothness or over-cleanliness that comes with the reduction of entropy…”
I also entered the second of van Houtryve’s prompts and got this back:

It was encouraging to see an accurate response and a refusal to create a false image in this instance. This demonstrates that the programmers for these foundation AI models have the capacity to create guardrails against disinformation.
However, that should not lull us into thinking that things have improved in the last year or so. Firstly, the large AI companies sell APIs to their technology that enable consumers to develop their own versions of the model with little, if any, regulation.
Second, not all of the major companies have instituted guardrails. While writing this article, I went back to Midjourney, entered van Houtryve’s second prompt on the “WMD labs,” and got these disturbingly realistic pictures.




Conclusion
GPT’s evident capacity to produce photorealistic images and video poses enormous risks for those of us concerned with the production of accurate, authentic, and verifiable reporting.
At the same time, the increasing understanding of the power of GPTs has given visual journalism an opportunity to be better recognized for its contribution to documentation and reporting. For too long, visual journalism has not had a seat at the table where discussions about the future of journalism are taking place. The obvious risks of synthetic media have paradoxically created an opening for a statement about the importance and necessity of trustworthy imagery. Everyone in the field needs to get involved.
Since photography was invented in the early 19th century, the boundary between the real and the unreal, the accurate and the inaccurate, has been contested. In the 21st century, faced with the challenges of AI, we can not propose returning to a simpler time when (allegedly) everyone believed photos because that is a misplaced nostalgia. Instead, we must think through what we want images to do and work to secure their integrity.
In my 2014 report on the integrity of the image, in a conclusion that rings even more true today, I said that a broader approach to verification was needed:
Shifting our focus from what images are to what images do requires us to make the purpose of images, the work of images, the function of images, what producers want them to do, and what consumers expect them to do, our principal concerns. This is very different from contemporary claims about showing the real. It means that if we want an image to work for news and documentary purposes, it will have to satisfy a range of criteria much more stringent than an image designed for art or entertainment. These criteria would include the techniques of its processing, but should also take into account every dimension of the image’s production, from conception to circulation. Such criteria could then become data points that would allow the image to be verified.
I proposed that the key elements in this process of verification would be built on transparent practices that included:
Image verification via a digital audit trail and workflow of image production (something that is now realizable through the Content Authenticity Initiative and the C2PA standard, which VII Foundation photographers have trialed).
Personal verification: a biographical statement about the image maker, their previous work, and, most importantly, a statement of their general perspective and where they are coming from.
Project verification: records showing who funded the commission, who provided the logistics, and details on anything from the field that could influence how the image or story was compiled (to which I would now add details about the research done before the beginning of the commission)
This approach intersects with the argument in Paul Lowe and Jennifer Good’s 2017 book Understanding Photojournalism (especially chapter 8) about how photographers need to see themselves as authors in order to be credible witnesses, and it chimes with the conclusion of Fred Ritchin in his new book, The Synthetic Eye: Photography Transformed in the Age of AI:
Serious photographers today will have to reconsider their mission in light of the changing culture. They need to commit to a transparency that clarifies their strategies for the reader and provides more context to anchor and augment the photograph (p. 207).
Since nearly 60% of people reportedly worry about what is real and what is fake on the internet, there remains a considerable demand for verifiable information and images that enhanced transparency from visual journalists can satisfy.
Let me conclude with a technical finding from a study of AI-generated images that bolsters the importance and demand for accurate and verifiable images. In a research paper entitled “Nepotistically Trained Generative-AI Models Collapse,” Matyas Bohacek and Hany Farid found that “when retrained on even small amounts of their own creation, these generative-AI models produce highly distorted images. We also show that this distortion extends beyond the text prompts used in retraining, and that once poisoned, the models struggle to fully heal even after retraining on only real images.”

In other words, if AI models have even a small amount of AI-generated images in their training data, that data is “poisoned,” the models break down and can no longer produce photo-realistic imagery. To maintain their capacity to generate photo-realistic fakes, AI models require authentic, human-made images. Let us see if that fact can be leveraged into more support for verifiable photography and visual journalism.
A lot of human work is needed to make AI systems function. Training data often has to be labeled manually, and these jobs can be found on Amazon’s Mechanical Turk (mTurk) platform, where individuals undertake tasks for a few cents a time. See Rusell Brandom, “When AI Needs a Human Assistant,” The Verge, 12 June 2019. This work is also done outside the US: “Gebru and her colleagues have also expressed concern about the exploitation of heavily surveilled and low-wage workers helping support AI systems; content moderators and data annotators are often from poor and underserved communities, like refugees and incarcerated people. Content moderators in Kenya have reported experiencing severe trauma, anxiety, and depression from watching videos of child sexual abuse, murders, rapes, and suicide in order to train ChatGPT on what is explicit content. Some of them take home as little as $1.32 an hour to do so.” Lorena O’Neil, “These Women Tried to Warn Us About AI,” Rolling Stone, 12 August 2023.
As models have grown, their environmental impact (especially through energy consumption and demands on water) has accelerated. See UN Environmental Program, “AI has an environmental problem. Here’s what the world can do about that” (no date), and Adam Zewe, “Explained: Generative AI’s environmental impact,” MIT News, 17 January 2025.
Copyright and intellectual property rights are significant ethical issues for the companies producing AI models. We’ve recently learned how Meta used the Library Genesis database of 7.5 million pirated books and 81 million pirated research papers to train its LAMA3 model. See Alex Reisner, “The Unbelievable Scale of AI’s Pirated-Books Problem,” The Atlantic, 20 March 2025. I used the search tool for LibGen that The Atlantic provided and found that all three of my books on international relations are in the database and have, therefore, been used by Meta.
For more details on algorithmic racism, see my interview with Mutale Nkonde, CEO of AI For the People.
For other articles with visualizations of diffusion models, see Adiyata Singh, “How Does DALL-E2 Work?, Medium, 27 April 2022, and Chris McCormick, “How Stable Diffusion Works,” Blog, 22 December 2022. It is important to note that as much as generative AI has developed its capabilities, it continues to be a mechanical process founded on probability calculations and, therefore, remains a long way from the dream of Artificial General Intelligence (AGI). AGI is the idea that it will be possible to build a technology that replicates the human brain with an autonomous, creative, reasoning, and sentient force backed by such vast computing power that it will exceed human knowledge. This is the utopian mission of AI evangelists and the dystopian nightmare of those who think AI poses an existential threat to humanity.
I discussed the meaning and implication of computational photography in my 2014 research report for World Press Photo, The Integrity of the Image.
These coronation party images were produced with a combination of generative AI (Midjourney 5.1 with prompts detailing the camera angle, frame, ISO, aperture, lighting style, camera type, and Adobe Firefly) in conjunction with Adobe Photoshop. There is much concern and debate about the impact of generative AI on employment in the creative industries. See, for example, Melanie A. Zaber, “The AI Playbook: What Other Sectors Can Learn from the Creative Industry's Fight Against AI,” RAND, 1 October 2024, and Queen Mary University of London, “Creative industry workers feel job worth and security under threat from AI,” 23 January 2025.